typedefstructLOCKTAG { uint32 locktag_field1; /* a 32-bit ID field */ uint32 locktag_field2; /* a 32-bit ID field */ uint32 locktag_field3; /* a 32-bit ID field */ uint16 locktag_field4; /* a 16-bit ID field */ uint8 locktag_type; /* see enum LockTagType */ uint8 locktag_lockmethodid; /* lockmethod indicator */ } LOCKTAG;
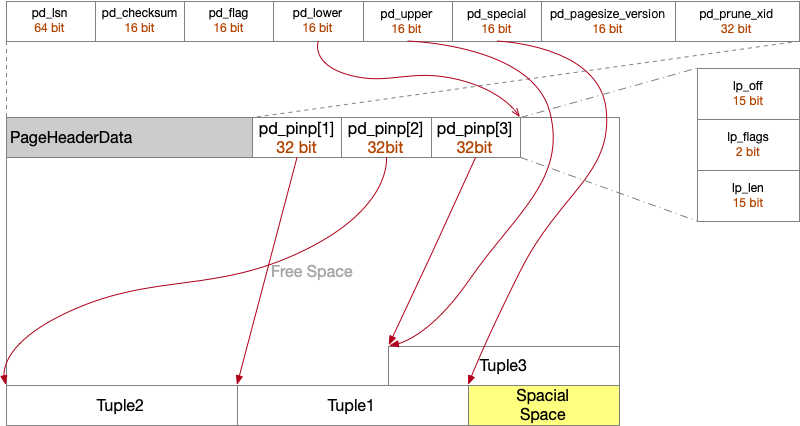
/* * disk page organization * * space management information generic to any page * * pd_lsn - identifies xlog record for last change to this page. * pd_checksum - page checksum, if set. * pd_flags - flag bits. * pd_lower - offset to start of free space. * pd_upper - offset to end of free space. * pd_special - offset to start of special space. * pd_pagesize_version - size in bytes and page layout version number. * pd_prune_xid - oldest XID among potentially prunable tuples on page. * * The LSN is used by the buffer manager to enforce the basic rule of WAL: * "thou shalt write xlog before data". A dirty buffer cannot be dumped * to disk until xlog has been flushed at least as far as the page's LSN. * * pd_checksum stores the page checksum, if it has been set for this page; * zero is a valid value for a checksum. If a checksum is not in use then * we leave the field unset. This will typically mean the field is zero * though non-zero values may also be present if databases have been * pg_upgraded from releases prior to 9.3, when the same byte offset was * used to store the current timelineid when the page was last updated. * Note that there is no indication on a page as to whether the checksum * is valid or not, a deliberate design choice which avoids the problem * of relying on the page contents to decide whether to verify it. Hence * there are no flag bits relating to checksums. * * pd_prune_xid is a hint field that helps determine whether pruning will be * useful. It is currently unused in index pages. * * The page version number and page size are packed together into a single * uint16 field. This is for historical reasons: before PostgreSQL 7.3, * there was no concept of a page version number, and doing it this way * lets us pretend that pre-7.3 databases have page version number zero. * We constrain page sizes to be multiples of 256, leaving the low eight * bits available for a version number. * * Minimum possible page size is perhaps 64B to fit page header, opaque space * and a minimal tuple; of course, in reality you want it much bigger, so * the constraint on pagesize mod 256 is not an important restriction. * On the high end, we can only support pages up to 32KB because lp_off/lp_len * are 15 bits. */
typedefstructPageHeaderData { /* XXX LSN is member of *any* block, not only page-organized ones */ PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog * record for last change to this page */ uint16 pd_checksum; /* checksum */ uint16 pd_flags; /* flag bits, see below */ LocationIndex pd_lower; /* offset to start of free space */ LocationIndex pd_upper; /* offset to end of free space */ LocationIndex pd_special; /* offset to start of special space */ uint16 pd_pagesize_version; TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */ ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array */ } PageHeaderData;
ALTER USER 'root'@'localhost' IDENTIFIED BY '12345';
CREATE DATABASE wordpress_db; CREATE USER 'wp_user'@'localhost' IDENTIFIED BY 'password'; GRANT ALL PRIVILEGES ON wordpress_db.* TO 'wp_user'@'localhost'; FLUSH PRIVILEGES; EXIT;
安装wordpress
1 2 3 4 5
cd /var/www/html wget https://wordpress.org/latest.tar.gz tar -xvzf latest.tar.gz chown -R www-data:www-data /var/www/html/wordpress chmod -R 755 /var/www/html/wordpress
demo=# SELECT* FROM pg_ls_waldir() WHERE name ='0000000100000001000000EB'; name | size | modification --------------------------+----------+------------------------ 0000000100000001000000EB |16777216|2025-07-2818:41:49+08 (1row)