Lehman–Yao B-tree
1. Lehman–Yao B*-Trees
Lehman–Yao构造了一个供并发进程使用的数据结构。该数据结构是 Wedekind提出的 B*-树的一个简单变体(其基础是 Bayer 和 McCreight定义的 B 树)。
Lehman–Yao B*-树定义如下。
1.1 定义
- Each path from the root to any leaf has the same length, h.
- 内部节点(非 root、非叶子)至少要有 k + 1 个孩子(sons)。 (k is a tree parameter; 2k is the maximum number of elements in a node, neglecting the “high key,” which is explained below.)
- root要么是页节点要么至少有两个孩子(sons)
- 每个node最多有2k+1个孩子(sons)
- Lehman–Yao B-tree中的所有数据的键(key)都存储在叶子节点中,叶子节点还包含指向数据库记录的指针(每一条记录都与一个 key 对应)。
非叶子节点包含指针,以及用于沿着这些指针继续查找的 key 值(b+ tree)。
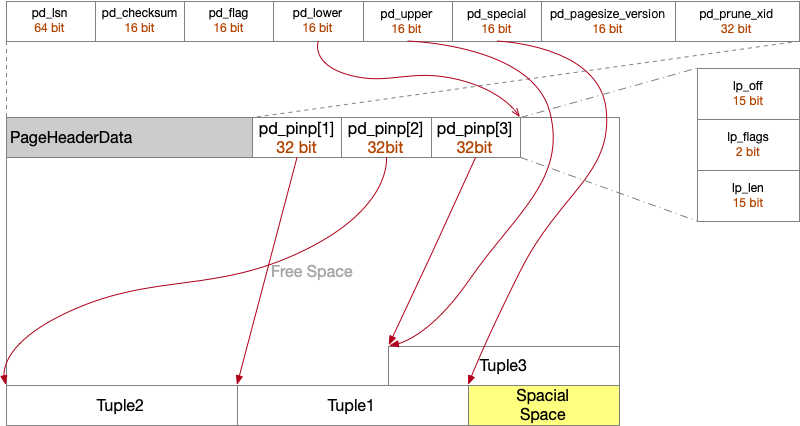
B*-树的节点看起来如图 1 所示。Ki 表示 key 域的实例Pi 表示指针。Pi 可以指向其他节点,或者——在叶子节点的情况下——指向与存储在叶子节点中的 key 值关联的记录。这种安排使得在我们的模型中,叶子节点和非叶子节点的结构基本相同。M 是一个标记,用于指示该节点是叶子节点,它占据了非叶子节点中第一个指针的位置。图 2 显示了一个 B*-树示例。
1.2 Sequencing(顺序规则)
- 每个节点内部,key 按升序排列。
- 在 B*-tree 中,有时会在非叶子节点追加一个额外的值,称为 “high key”(见图 3)。
- 在任意节点 N 中,每个指针 Pi 指向一个子树 Ti(Pi 指向的节点为 Ti 的根)。Ti 中存储的 key 值被 Pi 左右的两个 key (Ki 和 Ki+1)界定。 这就给非叶子节点提供了一组 (pointer, value) 对 其中,k0 = -∞(在 N 中物理上不存在),K2k+1 = high key(如果存在),high key 提供了 Pi 指向的子树的上界,因此它也是以 N 为根的子树中所有值的上界。
1
key(Ti) ∈ (Ki-1, Ki]
叶子节点 定义类似(见图 3):Ki = 叶子中存储的 key;Pi = 指向对应记录的指针
1.3 Insertion Rule(插入规则)
- 如果一个叶子节点的条目(entries)少于 2k 个,那么一个新的条目以及指向其对应记录的指针可以直接插入到该节点中。
- 如果一个叶子节点已有 2k 个条目,则插入新的条目时,需要通过将该节点分裂为两个节点来进行,每个新节点包含原节点一半的条目。新的条目会被插入到这两个节点中的一个(在合适的位置)。由于其中一个节点是新创建的,因此必须在原单节点的父节点中插入一个新的指针。这个新的指针指向新节点;新的键值是对应于原节点拆分后左半部分的键值。此外,需要为这两个新节点分别设置高键(high key)。图 4 展示了一个节点分裂的示例。
- 对非叶子节点的插入操作与叶子节点完全相同,只是指针指向的是子节点,而不是数据记录。
一个节点(按照上面给出的规则),如果条目数少于 2k,则称其为“安全节点”(就插入操作而言),因为插入可以通过对该节点的简单操作完成。同样,如果一个节点有 2k 个条目,则称其为“非安全节点”,因为必须进行分裂操作。对节点的删除操作也有类似的定义:如果删除可以在节点内完成而不会影响其他节点,则该节点称为“安全节点”;反之,如果删除会影响其他节点,则称为“非安全节点”。也就是说,如果节点的条目数多于 k + 1,则安全;如果恰好有 k + 1 条目,则非安全。
一个简单的例子就足以说明,对 B*-树进行并发操作的简单做法是错误的。
考虑图 5a 所示的 B*-树片段。假设有两个进程:一个搜索值 15,另一个插入值 9。插入操作应当导致树结构修改为图 5b 所示的样子。现在考虑下面这一系列操作:
| select(15) | insert(9) |
|---|---|
| C<-read(x) | |
| A<-read(x) | |
| exam C;get ptr to y | |
| exam A;get ptr to y | |
| A <- read(y) | |
| insert 9 into A; must split into A, B | |
| PUT(B, Y’) | |
| PUT(A, Y) | |
| Add to node x a pointer to node y’. | |
| C <- read(y) | |
| error!15 not found |
问题在于,搜索操作首先返回指向 y 的指针(从 X 获得),然后才读取包含 y 的页面。在这两个操作之间,插入操作已经修改了树的结构。
2. Previous Approaches
前面的例子表明,对并发 B 树问题采取简单做法是行不通的:如果不防范并发操作带来的潜在问题,多个进程的操作可能导致结果不正确。为了更好地理解这个问题,我们在此简要概述一些已经提出的其他方法和解决方案。
针对并发 B 树问题的第一个解决方案是由 Samadi 提出的.他的做法是最直接的一种,并且是最早考虑并发问题的方法。该方案简单地使用信号量来独占锁定任何一次树结构修改可能经过的整条路径。这实际上锁定了受影响的最高节点所在的整个子树
Bayer 和 Schkolnick 提出的算法对 Samadi 的方法进行了实质性的改进。他们提出了一种用于 B*-树并发操作的方案;该方案包含一些参数,可以根据所需的并发程度和类型进行设置。
首先,修改操作会对树的上部节点加写者排他锁(writer-exclusion locks)(这种锁只排斥其他写者,而不会阻止读者)。
当需要真正进行修改操作时,会施加独占锁(exclusive locks),大多应用在树的下部节点。
这种对独占锁的稀疏使用提高了算法的并发性能。
Miller 和 Snyder [12] 研究了一种方案,该方案锁定树中一个有界大小的区域。该算法使用先导锁(pioneer locks)和跟随锁(follower locks),以防止其他进程进入当前进程正在修改的树区域。被锁定的区域沿树向上移动,同时执行相应的修改操作.在使用队列管理的锁策略的帮助下,沿树向下移动的读者可以“越过”被锁定的区域,从而避免死锁。这种算法与本文提出的算法的权衡在于:本文的算法锁定树的区域明显更小,但需要对普通的 B-tree 或 B*-tree 结构进行稍微的修改,以便支持并发。
Ellis [6] 提出了一种针对 2-3 树的并发解决方案。文中采用了几种方法以提高并发能力,并且(据称)这些方法可以很容易地推广到 B 树。
该论文应用了两种思想:一是在相反方向上对一组数据进行读写(由 Lamport [11] 提出);二是允许数据结构暂时出现轻微退化,同时允许进程不必立即完成操作,可以将工作推迟到更合适的时间再执行。
Guibas 和 Sedgewick [6a] 提出了一种针对平衡树的统一“双色框架”(dichromatic framework)。这是一种研究平衡树的简化方法:它将所有平衡树方案归约为“带颜色”的二叉树的特例,并具有概念上的清晰性。这些作者利用他们的框架研究一种自上而下的并发锁定方案,其中包括在沿树向下访问时对“几乎满的”节点进行分裂。我们预计,他们的方案将锁定比我们的方案更多的节点(降低并发性),并且需要略多的存储空间。
另一种针对 B 树并发操作的方法目前正在由 Kwong 和 Wood [10] 进行研究。
3. Blink-Tree for Concurrency
B-link 树是一种在 B*-树基础上修改而成的结构,它在每个节点中增加了一个“链接(link)”指针字段(记作 P2k+1 ——见图 6)。
(B-link-tree 的发音是 “Blink-tree”。)
这个链接指针指向当前节点所在层的下一个节点;只有在该层最右侧的节点中,这个链接指针才是空指针(null)。这样的链接指针定义是自洽的,因为所有叶子节点都位于树的同一层。
因此,在 B-link 树中,同一层的所有节点都被连接成一条链表,如图 7 所示。
Link 指针的目的,是提供一种到达某个节点的额外途径。
当一个节点因为数据溢出而被分裂时,原来的单一节点会被两个新的节点取代。
在分裂后:
第一个新节点的 link 指针指向第二个新节点;
第二个新节点的 link 指针则保存了原来旧节点的 link 指针内容。
通常情况下,第一个新节点会占用旧节点在磁盘上的同一个物理页面。
设计这个方案的意图是:
因为这两个新节点被 link 指针连接起来,在父节点中的正确指针尚未更新之前,它们在功能上仍然等价于原来的那个单一节点。
Blink-tree 的精确查找与插入算法将在接下来的两个章节中给出。
对于树中的任意一个节点(处于某一层且不是该层的第一个节点),通常会有两种指针指向它:
来自其父节点的“子指针”(son pointer),以及
来自其左兄弟节点的 link 指针。
当一个节点被插入到树中时,这两个指针之中必定有一个会先被创建。
我们规定:在这两个指针中,link 指针必须最先存在。
也就是说,一个节点在树中出现时,可以暂时没有父节点的指针指向它,但必须已经有一个左兄弟指向它的 link 指针。
这种结构依然被定义为一个合法的树结构,因为新的“右兄弟”节点可以通过“左兄弟”到达。(这两个兄弟节点在功能上仍然可以视作一个节点。)
当然,为了保证良好的查找效率,来自父节点的指针必须尽快补上。
Link 指针的优势在于:它会在节点发生分裂时同步建立。
因此,即使针对新节点的常规树指针尚未全部更新完毕,link 指针仍可作为一种“临时修补”机制,使并发操作保持正确性。
当查找键大于节点的最大键值(由 high key 标识)时,这表明树结构已经发生变化,此时应通过 link 指针继续访问右兄弟节点。
虽然这种方式略低效一些(因为需要额外一次磁盘读取来跟随 link 指针),但它仍然是到达目标叶子节点的正确路径。
由于节点分裂本身属于例外情况,link 指针的实际使用频率应该非常低。
Blink-tree 结构的另一个优点是:在对树进行顺序遍历时,link 指针可以用于快速按“按层次优先(level-major)”的顺序检索树中的所有节点,或者,例如,只检索所有叶子节点。
4. THE SEARCH ALGORITHM
4.1 算法示意图(Algorithm Sketch)
要在树中查找一个值 v,搜索过程从根节点开始,沿树向下比较 v 与每个节点中的键值。在每个节点中,比较键值后,决定沿节点中哪条现有指针继续向下搜索,指示应沿该指针前往下一层节点,或直接到达叶子(记录)节点。
如果搜索过程中检查某个节点时,发现该节点中的最大值小于 v,则可以推断出当前节点发生了一些变化,而这些变化在搜索检查其父节点时尚未反映到父节点中。
这意味着当前节点已经被分裂成两个(或更多)新的节点。
此时,搜索必须纠正其在树中的位置错误:不再按照普通的父节点子指针(son pointer)前进,而是沿新分裂节点的 link 指针继续搜索。
搜索过程最终会到达 v 应该所在的叶子节点(如果 v 存在的话)。此时,该节点要么包含 v,要么不包含 v 且节点中的最大值大于 v。
因此,该算法能够正确地判断 v 是否存在于树中。
4.2 算法
搜索(Search)
该过程用于在树中查找一个值 𝑣。如果 𝑣 存在于树中,过程结束时:𝐴包含包含 𝑣 的节点 𝑡
包含指向与 𝑣 关联的记录的指针;如果 𝑣 不存在于树中,𝐴 将包含 𝑣 如果存在的话应该所在的节点。
1 | Search(v): |
下文算法中使用的符号在第 2 节中定义。
在此过程中,我们使用了一个辅助操作 scannode,其定义如下:
x <- scannode(u, A) denotes the operation of examining the tree node in memory block A for value u and returning the appropriate pointer from A (into x).
1 | procedure search(u) |
请注意,这种搜索过程非常简单,其行为与非并发搜索完全相同,将 link 指针与其他指针同等对待。
还要注意,该过程不进行任何形式的加锁。
这与传统的数据库搜索算法形成对比(例如 Bayer 和 Schkolnick [3] 所述),在那些算法中,所有搜索操作都会对它们访问的节点进行读锁。
5. THE INSERTION ALGORITHM
5.1 算法示意图(Algorithm Sketch)
要在树中插入一个值 𝑢 我们执行的操作与前面描述的搜索过程类似。从根节点开始,沿树向下扫描,直到到达应该包含 𝑢 的叶子节点。同时,我们在下降过程中记录每一层中被访问过的最右节点。沿树的下降过程实际上就是在搜索 𝑢 的正确插入位置(比如称该节点为节点 𝑎 )。
将值 u 插入叶子节点时,可能需要对该节点进行分裂(当节点不安全时)。
在这种情况下,我们对节点进行分裂(如图 8 所示),用两个新节点 a’(a 的新版本,写回同一磁盘页面)和 b’ 替换原来的节点 a。节点 a’ 和 b’ 的内容与原节点 a 相同,只是增加了值 u。随后,我们沿着先前记录的搜索路径回溯树的上层,在叶子节点的父节点中插入新节点 b’ 的条目以及 a’ 的新 high key。
死锁的避免是由锁定方案的良序性(well-ordering)所保证的,如下所示。
需要注意的是,当我们沿树向上回溯时,由于节点可能被分裂,我们必须插入新指针的节点可能并不是下降过程中经过的那个节点。换句话说,我们在下降过程中使用的旧节点可能已经被分裂;此时,正确的插入位置就在原预期插入位置右侧的某个节点。我们通过 link 指针 来找到这个节点。
5.2 算法
在下文的算法中,有些过程被视为原语操作(就像上文的 scannode 一样),因为它们容易实现,并且其具体操作对本文的目的而言并不重要。例如:
A <- node.insert (A, w, v) denotes the operation of inserting the pointer w and the value v into the node contained in A.
u <- allocate(2 newpage for B) denotes the operation of allocating a new page on the disk. The node contained in B will be written onto this page, using the pointer u.
“A, B <- rearrange old A, adding ..” denotes the operation of splitting A into two nodes, A and B, in core.
插入(Insert)。该算法负责将一个值 v(以及其关联的记录)插入到树中。当算法结束时,值 v 已成功插入到树中,并且在必要的情况下,算法会在从叶子向上回溯的过程中对相应的节点进行分裂。
1 | procedure insert(v) |
Move.right. This procedure, which is called by insert, follows link pointers at a given level, if necessary.
1 | procedure move.right |
需要注意的是,该过程在向上回溯树时是 逐层进行的。此外,同时最多只会锁定三个节点,而这种情况发生的频率相对较低:仅在插入分裂节点的指针时,需要沿 link 指针向右移动 的情况下才会出现。此时,被锁定的节点包括:
分裂节点的原始左半部分
分裂节点上一层的两个节点
在插入沿右链移动的过程中需要锁定它们。
与传统方法相比(即只有在确定节点为安全节点时才释放锁),这种做法在 锁粒度和并发性能上都有显著改进。
该算法的正确性依赖于以下事实:树结构的任何变化(即任何节点的分裂)都会伴随一个 link 指针。节点分裂时,条目总是被移动到树的右侧,在右侧的新节点可以通过 link 指针被访问到,从而保证树的结构在并发操作下仍然可达且正确。
具体来说,对于任何层级的一个对象(与某个值相关联),我们总能大致知道它的正确插入位置,即我们在该层搜索时经过的“记录节点”。如果该对象的正确插入位置发生了移动,这种移动方式是可预知的:也就是节点分裂向右,留下的 link 指针使得搜索或插入操作仍然能够找到它。因此,从旧的“预期”插入位置开始,始终可以访问到对象的正确插入位置。
6 CORRECTNESS PROOF
为了证明系统的正确性,我们需要证明以下两个命题对每个进程都成立:
- 该进程不会发生死锁(定理 1);
- 当进程终止时,它已经正确地完成了所需的操作。
更具体地说:
- 所有磁盘操作都保持树结构的正确性(定理 2)
- 除正在进行修改的进程之外,所有其他进程看到的树都是一致的(交互定理 3)。
6.1 无死锁性(Freedom from Deadlock )
首先,我们开始证明系统不存在死锁。
为此,我们对节点施加一个顺序:跨层从下到上、同层从左到右。下面的引理(Lemma:一种 辅助性结论,用于证明后续更大、更重要的定理(Theorem))对这一点进行了严格定义。
引理 1 插入操作对节点加锁遵循一个良序(well-ordering:严格定义的、有序的顺序关系)关系
证明 考虑在树的节点集合上定义如下顺序关系(<):
- 在任意时刻 t,如果两个节点 a 和 b 与树根的距离不同(不在同一层级),那么当且仅当 b 离树根更近(处于更高层级)时,我们称 a < b。
- 如果 a 和 b 与树根的距离相同(在同一层级),那么当且仅当 b 能通过从 a 开始沿着一条或多条链接指针到达(即 b 在 a 的右侧)时,我们称 a < b。
通过检查插入算法我们可以看到:如果在时间 t₀ 时 a < b,那么在所有 t > t₀ 的时间点都仍然有 a < b。因为节点创建过程只是把一个节点 x 分裂成两个新节点 x′ 和 x″,并且满足 x′ < x″,而且
1 | y<x⟺y<x′ |
和
1 | x<y⟺x′′<y |
因此,这些节点形成了一个良序关系,插入者按照良序对节点加锁。一旦在某个节点上加锁,它不会再对该节点之下的任何节点加锁,也不会对同一层中位于左侧的节点加锁。
因此,插入者按照给定的良序对节点加锁。证毕。
由于插入者是唯一对节点加锁的过程,我们可以立即得到以下定理。
定理 1:无死锁性。 给定的系统不会产生死锁。
6.2 树结构修改的正确性
为了确保树结构的完整性,我们必须检查所有修改树结构的操作。首先,需要注意的是,树结构的修改只能通过 “put” 操作 来完成。插入过程中算法中有三个地方会执行 put 操作:
- 对安全节点重写时使用 “put(A, current)”。
- 对不安全节点的最右节点使用 “put(B, u)”。通过该操作,我们写入由节点分裂形成的两个新节点中的第二个节点。
- 对不安全节点使用 “put(A, current)”。这里写入的是两个新节点中的第一个(最左节点)。实际上,我们重写了树中已存在的页面(节点),并修改该页面的链接指针,使其指向由 “put(B, …)” 写入的新节点。
注意,在算法中(针对不安全节点),“put(B, u)” 紧接在 “put(A, current)” 之前执行。我们将在下面的引理中证明,这种顺序实际上将两个 put 操作简化为本质上的一次操作。
引理 2. 操作 ‘put(B, u); put(A, current)’ 相当于对树结构的一次修改。
证明. 假设这两个操作分别写入节点 b 和 a。在执行 “put(B, u)” 时,没有其他节点指向正在写入的节点 b,因此该 put 操作对树结构没有影响。现在,当执行 “put(A, current)” 时,该操作修改了 current 指向的节点(节点 a)。修改内容包括将节点 a 的链接指针指向 b。此时,b 已经存在,并且 b 的链接指针指向与 a 的旧版本相同的节点。这样就实现了同时修改 a 并将 b 引入树结构。证毕。
定理 2. 所有 put 操作都能正确地修改树结构。
证明
case 1: 对安全节点执行 “put(A, current)”。该操作只修改树中一个已加锁的节点,因此树的正确性得到保持。
case 2: 对不安全节点执行 “put(B, u)”。该操作不会改变树结构。
case 3: 对不安全节点执行 “put(A, current)”。根据引理,该操作既修改了当前节点(比如 a),又将另一个节点(比如 b,通过 “put(B, u)” 写入)引入树结构。与情况 1 类似,节点 a 在执行 “put(A, current)” 时已加锁。本例的区别在于该节点是不安全的,需要分裂。但根据引理,我们可以通过一次操作完成,保持树结构的正确性。证毕
6.3 正确的交互
我们还需要证明,无论插入过程对树进行何种修改,其他进程仍能正确操作。
定理 3:交互定理。 插入过程的操作不会破坏其他进程操作的正确性。
为了证明该定理,我们首先考虑搜索过程与插入操作的交互情况,然后考虑两个插入过程的交互情况。一般来说,为了证明插入者的操作不会破坏其他进程的正确性,我们需要考虑该进程相对于该操作的行为。在所有情况下,该操作都是原子的。
假设插入者在时间 t0 对节点 a 执行一次 “put” 操作。考虑另一个进程在时间 t′从磁盘读取节点 a 的情况。由于假设 “get” 和 “put” 操作是不可分割的,要么 t′<t0,要么 t0 < t′。我们将在下面的引理中证明,后一种情况不会产生问题。
引理 3
如果进程 𝑃 在某个时间 𝑡′ > 𝑡0 读取节点 𝑎,其中 𝑡0 是插入进程 I 修改节点 𝑎 的时间,那么这一修改不会影响进程 𝑃 的正确性。
证明. 考虑进程 P 通过节点 a 的路径。进程 P 在到达节点 a 之前所经过的路径不会被插入进程 I 改变。此外,根据上面的定理 2,进程 I 对树结构所做的任何修改都会产生一个正确的树(well-ording)。因此,进程 P 在 a 节点开始的路径(在时间 t>t′t > t’t>t′)将无论修改如何都能正确执行。证毕。
为了便于将定理的证明分解成不同情况,这里列出在一个节点上对一个值可能执行的三种插入类型。
类型 1. 简单地将一个值及其关联指针添加到节点中。当节点是安全的(safe)时发生这种类型的插入。
类型 2. 对节点进行分裂,并将插入值放入分裂节点的左半部分。左半部分仍然是原来被分裂的节点。
类型 3. 类似地,对节点进行分裂,并将插入值放入分裂节点的右半部分。右半部分是新分配的节点。
现在我们开始定理的证明。我们注意到,定理的正确性涉及几个方面(情况),并将分别证明这些情况。
证明. 根据引理 3,只需考虑搜索或插入进程 𝑃 在插入进程 𝐼 修改节点之前开始读取该节点的情况。
第 1 部分. 考虑插入进程 I(在时间 t0 修改节点 n)与搜索进程 S(在时间 t′< t0读取节点 n)之间的交互。记 n′ 为修改后的节点。(本节的论证同样适用于另一插入进程 I′与进程 I 交互的情况,且 I′正在执行搜索。)需要考虑的操作顺序是:S 读取节点 n;然后 I 将节点 n 修改为 n′;然后 S 根据 n 的内容继续搜索。
考虑三种插入类型:
| Type 1 | 进程 I 对节点 n 执行一次简单插入。如果 n 是叶子节点,插入进程不会改变任何指针。其结果等同于序列调度中 S 在 I 之前运行的情况。如果 n 是非叶子节点,则在 n 中插入一个指向下一层某节点 m′的指针/值对。假设 m′是通过将 I 分裂为 I′ 和 m′ 创建的。唯一可能的交互是 S 在插入指向 m′ 的指针之前已经获得了指向 I 的指针。此时指向 I 的指针指向了 I′,而 S 将使用 I′中的 link pointer 访问 m′。因此搜索仍然是正确的。 |
| Types 2 and 3 | 节点 n 在插入过程中被分裂为节点 n1′ 和 n2′。对于叶子节点的情况,搜索在 n 上的结果与在 n1′和 n2′上的结果相同,除了新插入的值 S 无法找到。 如果 n 不是叶子节点,则其下层的某个节点发生了分裂,导致一个新的指针/值对被插入节点 n,从而使 n 本身也分裂。根据归纳法,下层节点的分裂是正确的。根据引理 3,下层节点的搜索也是正确的。因此,我们只需证明节点 n 的分裂是正确的。假设节点 n 分裂为节点 n1′ 和 n2′,它们包含与原节点 n 相同的指针集合,并增加了新插入的节点。则从节点 n 开始搜索,将到达下一层与从 n1′(带有指向 n2′的 link pointer)开始搜索时相同的节点集合。特殊情况是:如果搜索在读取节点 n 时,新插入的指针已经存在,本应沿该指针继续。此时实际跟随的指针位于新指针的左侧,这会将搜索引导到某个节点(假设为 k),它位于新指针指向的节点(假设为 m)左侧。然后沿 k 的 link pointer 最终到达 m,这仍然是正确的结果。(类型 3 的论证与类型 2 相同,只是新条目插入到新创建的半节点中,而不是旧半节点。但这对论证没有影响,因为节点在分裂发生前已被S读取。) |
第2部分。接下来我们考虑插入进程 I 与另一个插入进程 I’ 的交互情况。进程 I’ 可能正在搜索用于插入的正确节点、回溯到另一层,或者实际尝试将一个值/指针对插入节点 n。如果 I’ 正在搜索一个用于插入值/指针对的节点,则该搜索行为与普通搜索进程完全相同。因此,证明与上文针对搜索进程的证明相同。
第3部分。如果 I’ 因为下层节点分裂而需要回溯上行树,则 I’ 需要回到上层以便将指针插入到分裂节点的新半部分。
- 回溯是使用在下降过程中记录在栈中的信息完成的。
- 在每一层,被压入栈的节点是该层被检查过的最右侧节点。
- 考虑在将某个节点 n 压入栈和回溯时再次访问该节点之间可能发生的情况:该节点可能已经分裂过一次或多次,这些分裂会在节点 n 的“右侧”产生新的节点。
- 由于节点 n 右侧的所有节点都可以通过 link 指针访问,因此插入算法能够找到适当的位置插入值。
第四部分。如果进程 I’ 试图在节点 n 上进行插入,它会尝试锁定该节点。但进程 I 已经持有节点 n 的锁。最终,I 会释放该锁,I’ 再锁定该节点并将其读入内存。根据上面的引理,该交互是正确的,因为 I’ 的读取发生在 I 的插入之前。节点 n 要么就是插入的正确位置——此时 I’ 会执行插入;要么搜索必须沿节点的 link 指针访问其右兄弟。
LiveLock
我们在此指出,我们的算法并不能完全避免活锁(LiveLock)的可能性(即某个进程无限运行)。
如果一个进程因为不断跟随其他进程创建的 link 指针而无法终止,就可能发生这种情况。
然而,根据以下观察,我们认为在实际实现中这种情况极不可能成为问题。
在多处理器系统中,如果该进程运行在相对非常慢的处理器上,这种情况可能发生。
(1) 在我们所知的大多数系统中,处理器的运行速度大致相当。
(2) 在 B 树中,节点的创建和删除只占很小的比例,因此即使是较慢的处理器,也不太可能因节点的创建或删除而遇到困难(也就是说,它只需要跟随少量的 link 指针)。
(3) 在树的任意给定层上,只能创建固定数量的节点,从而限制了较慢处理器需要“追赶”的量。
我们认为,这些想法结合起来可以使实际系统中进程发生活锁的概率几乎为零(除非涉及的进程速度差异极大)。模拟可以帮助我们验证系统在“合理”条件下能够正常工作,并帮助确定进程相对速度的可接受范围。
在进程速度确实存在极大差异的情况下,我们可能会引入一些额外机制来防止活锁。实现这种机制有多种选择。本文不讨论避免活锁的完整方法,但其中一种方法可能是为每个进程分配优先级,优先级可能基于进程的“存在时间”。这将保证每个进程最终会终止,因为它最终会成为最“老”的进程,从而成为拥有最高优先级的进程。
7. DELETION
一种处理删除操作的简单方法是允许叶子节点中的条目少于 K 个。对于非叶子节点则不需要这样做,因为删除操作仅会移除叶子节点中的键;非叶子节点中的键仅作为其对应指针的上界,它在删除过程中并不会被移除。
因此,为了从叶子节点中删除一个条目,我们对该节点执行的操作与插入操作(尤其是插入情况 1)非常类似。具体来说,我们首先搜索出值 u 所在的节点,然后锁定该节点,将其读入内存,对内存中的副本删除值 u 后再将节点重写回磁盘。有时,这样会导致节点中条目数量少于 K。
该算法的正确性证明与插入操作类似。例如,死锁自由性的证明非常简单,因为删除操作只需要锁定一个节点。对于操作的正确性,如果一个搜索进程在删除值 u 之前读取了节点,它仍然会报告节点中存在 u,这与序列化调度(搜索操作先于删除操作执行)是一致的,因此搜索结果仍然正确。
我们刚描述的这种删除处理方法比需要处理节点下溢(underflow)和合并(concatenation)的方案要简单得多。在假设插入操作发生频率高于删除操作的情况下,这种方法几乎不需要额外存储空间。
当然,在删除操作过多导致树节点存储利用率过低的情况下,可以执行批量重组(batch reorganization)或者全树锁定的下溢操作(underflow operation)来重新组织树结构,以保证空间的合理利用。
8. 锁定效率(LOCKING EFFICIENCY)
显然,在并发方案中,至少需要一个锁,以防止不同进程同时更新同一个节点。
上文给出的插入操作方案,在任何时刻对任意进程使用的锁数量最多是一个常数(最多三个)。这种情况仅在特定情况下发生:当插入进程刚刚向某个节点(叶子节点或非叶子节点)插入条目,并导致该节点分裂时。在回溯树的过程中,为了向新分裂节点的一半插入指针,插入进程发现旧的父节点已经不再是正确的插入位置,因此必须沿包含父节点的这一层节点进行链式查找,以找到正确的插入位置。在整个操作过程中,同时锁定三个节点。
在每个节点容量较大的 B*-树中,这种类型的锁定操作发生的频率非常低。因此,除非有大量并发进程运行,否则该结构的锁冲突概率极低。
这种系统的行为可以通过模拟进行量化,模拟参数包括并发进程数量、每个节点的容量,以及搜索、插入和删除操作的相对频率。这样的模拟不仅可以评估当前方案的性能,也可用于与其他并发控制方案进行比较。
9. SUMMARY AND CONCLUSIONS
B 树在维护大型数据库时被发现非常有用。并发操作这样的数据具有明显优势,因为它允许多个用户同时共享数据;而且在大规模数据库中,用户的数据需求通常不会产生冲突,因此并发访问是可行的。
本文给出了一个算法,可以在 B 树的一种变体上执行正确的并发操作。该算法的特点是任意进程在任何时刻只需使用少量常数个锁。算法本身非常直接,其流程与顺序执行的算法仅有轻微差别。(可以通过模拟来量化本文算法与顺序算法或其他并发算法相比的效率提升。)
这一性能的实现依赖于对数据结构的一个小改动,使得当一个进程的位置因其他进程的操作而失效时,能够进行恢复(参见 [8])。
我们希望将这项工作扩展到更通用的并发数据库操作方案。理想的方案应当仅需对数据结构和顺序算法做极少量修改,同时能够保证当其他进程对数据结构做出改变使某进程的操作失效时,该进程能够正确恢复。
另一条未来研究方向是对算法的“并行化”:研究将一个(已充分理解的)顺序算法转换为并发算法的通用方法。目标是尽可能充分利用问题的并发特性,同时保证算法的正确性不受影响。