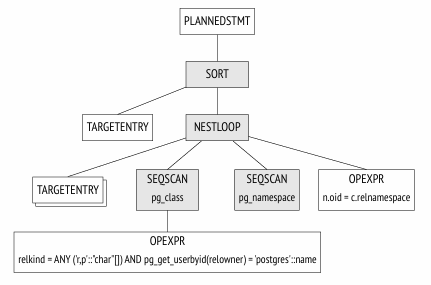
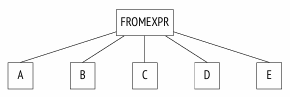
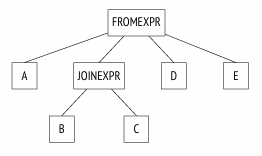
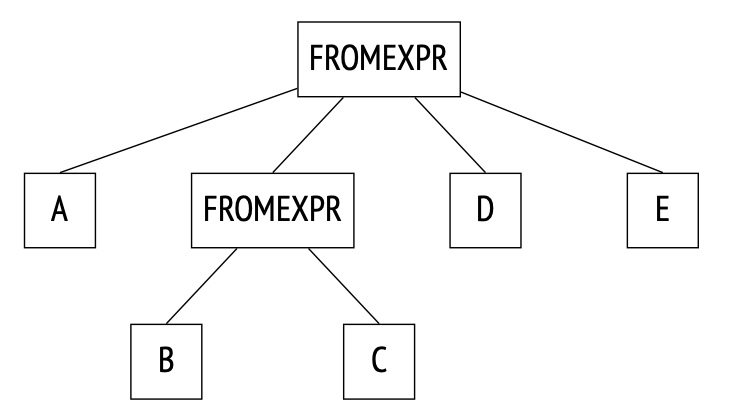
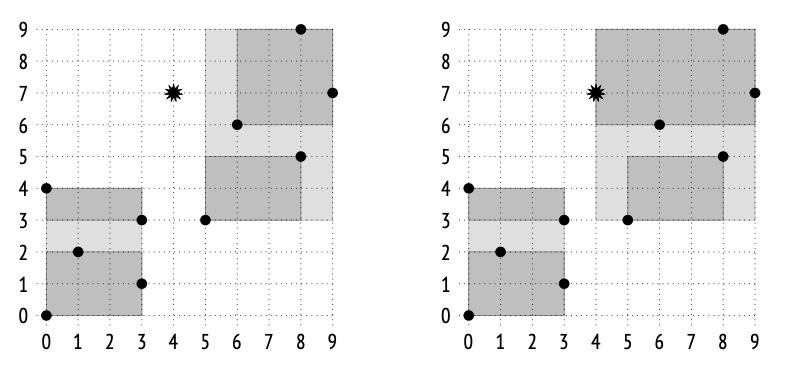
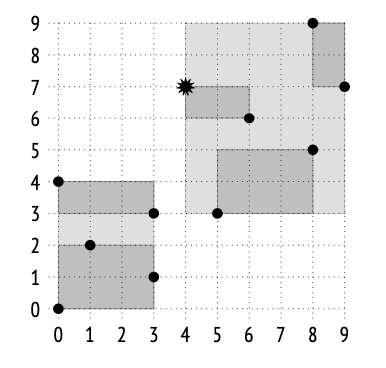
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| demo=# SELECT ctid, keys FROM gist_page_items(get_raw_page('airports_gist_idx', 0), 'airports_gist_idx' );
ctid | keys
(1,65535) | (coordinates)=("(-75.47339630130001,-0.12295600026845932),(-179.876998901,-43.810001373291016)")
(2,65535) | (coordinates)=("(-62.919601,-0.14835),(-74.9615020752,-54.93109893798828)")
(3,65535) | (coordinates)=("(-39.253101348877,-17.652299880981),(-62.1693,-62.1907997131)")
(4,65535) | (coordinates)=("(-14.3937,-0.6994310021400452),(-61.8465003967,-16.706899642899998)")
(5,65535) | (coordinates)=("(22.4692001343,-2.7174999713897705),(10.674076080322266,-34.554901123)")
(6,65535) | (coordinates)=("(63.361,-2.3089799880981445),(22.9993000031,-34.0881601675)")
(7,65535) | (coordinates)=("(177.97799682617188,-31.94029998779297),(115.401596069,-46.8997)")
(8,65535) | (coordinates)=("(-79.3834991455,28.20170021057129),(-177.38099670410156,0.9785190224647522)")
(9,65535) | (coordinates)=("(-51.0722007751,19.96980094909668),(-78.7492,0.0506640002131)")
(10,65535) | (coordinates)=("(128.707992554,-0.06239889934659004),(8.754380226135254,-30.83810043334961)")
(11,65535) | (coordinates)=("(153.56199646,-0.8918330073356628),(130.6199951171875,-31.8885993958)")
(12,65535) | (coordinates)=("(179.951004028,-0.547458),(154.67300415039062,-31.5382995605)")
(13,65535) | (coordinates)=("(-153.7039948,71.285402),(-176.64599609375,51.87799835205078)")
(14,65535) | (coordinates)=("(-128.576009,70.33080291750001),(-152.621994019,53.25429916379999)")
(15,65535) | (coordinates)=("(-104.26300048828125,39.90879822),(-122.8130035,24.072700500499998)")
(16,65535) | (coordinates)=("(-91.149597,37.9275016785),(-103.602996826,25.54949951171875)")
(17,65535) | (coordinates)=("(-68.36340332030001,31.9512996674),(-90.25800323486328,18.25149917602539)")
(18,65535) | (coordinates)=("(-2.269860029220581,31.9475002289),(-67.14849853515625,4.3790202140808105)")
(19,65535) | (coordinates)=("(-115.78199768066,63.20940017700195),(-127.36699676513672,40.1506996155)")
(20,65535) | (coordinates)=("(-96.6707992553711,62.462799072265625),(-114.903999329,37.649899)")
(21,65535) | (coordinates)=("(-83.29579926,37.24570084),(-95.984596252441,32.30059814)")
(22,65535) | (coordinates)=("(-83.3467025756836,48.06570053),(-96.38439941,37.74010086)")
(23,65535) | (coordinates)=("(-78.31999969,47.697400654599996),(-83.072998,32.00999832)")
(24,65535) | (coordinates)=("(-64.67859649658203,47.990799),(-77.98459625,32.36399841308594)")
(25,65535) | (coordinates)=("(-74.5280990600586,79.9946975708),(-126.7979965209961,48.0532989502)")
(26,65535) | (coordinates)=("(-13.746399879455566,82.51779937740001),(-72.2656021118164,32.697899)")
(27,65535) | (coordinates)=("(25.3379993439,39.828335),(-9.35523,0.0226000007242)")
(28,65535) | (coordinates)=("(1.7605600357100002,48.069499969499994),(-8.68138980865,40.471926)")
(29,65535) | (coordinates)=("(1.954759955406189,62.0635986328125),(-9.653610229492188,48.447898864746094)")
(30,65535) | (coordinates)=("(173.82899475097656,31.3253993988),(27.221700668300002,0.042386)")
(31,65535) | (coordinates)=("(7.8790798,61.583599090576),(2.040833,32.38410186767578)")
(32,65535) | (coordinates)=("(58.890499114990234,31.989853),(32.2400016784668,10.350000381469727)")
(33,65535) | (coordinates)=("(89.4672012329,31.909400939941406),(60.3820991516,8.30148983002)")
(34,65535) | (coordinates)=("(111.63999939,31.4281005859375),(90.30120086669922,8.09912014008)")
(35,65535) | (coordinates)=("(169.852005,31.919701),(113.069999695,8.178509712219238)")
(36,65535) | (coordinates)=("(17.439699172973633,52.59120178222656),(6.504444,32.6635017395)")
(37,65535) | (coordinates)=("(31.1583003998,52.527000427246094),(17.828399658203125,32.096801757799994)")
(38,65535) | (coordinates)=("(30.60810089111328,57.78390121459961),(6.57944011688,53.0475006104)")
(39,65535) | (coordinates)=("(31.044900894165,78.246101379395),(6.0741000175476,58.0994987487793)")
(40,65535) | (coordinates)=("(42.4826011658,61.88520050048828),(31.9197998046875,32.01139831542969)")
(41,65535) | (coordinates)=("(75.634444,63.566898345947266),(43.025978088378906,32.056098938)")
(42,65535) | (coordinates)=("(98.3414,73.51780700683594),(32.75080108642578,32.1)")
(43,65535) | (coordinates)=("(122.853996,71.97810363769531),(100.0989990234375,32.1506)")
(44,65535) | (coordinates)=("(177.74099731445312,71.697700500488),(123.48300170898438,32.482498)")
(44 rows)
|